mirror of
https://github.com/mudler/LocalAI.git
synced 2024-06-07 19:40:48 +00:00
* feat(sycl): Add sycl support (#1647) * onekit: install without prompts * set cmake args only in grpc-server Signed-off-by: Ettore Di Giacinto <mudler@localai.io> * cleanup * fixup sycl source env * Cleanup docs * ci: runs on self-hosted * fix typo * bump llama.cpp * llama.cpp: update server * adapt to upstream changes * adapt to upstream changes * docs: add sycl --------- Signed-off-by: Ettore Di Giacinto <mudler@localai.io>
This commit is contained in:
parent
16cebf0390
commit
1c57f8d077
7
.github/workflows/image-pr.yml
vendored
7
.github/workflows/image-pr.yml
vendored
@ -75,6 +75,13 @@ jobs:
|
||||
ffmpeg: 'true'
|
||||
image-type: 'core'
|
||||
runs-on: 'ubuntu-latest'
|
||||
- build-type: 'sycl_f16'
|
||||
platforms: 'linux/amd64'
|
||||
tag-latest: 'false'
|
||||
tag-suffix: 'sycl-f16-ffmpeg-core'
|
||||
ffmpeg: 'true'
|
||||
image-type: 'core'
|
||||
runs-on: 'arc-runner-set'
|
||||
- build-type: 'cublas'
|
||||
cuda-major-version: "12"
|
||||
cuda-minor-version: "1"
|
||||
|
||||
28
.github/workflows/image.yml
vendored
28
.github/workflows/image.yml
vendored
@ -122,6 +122,34 @@ jobs:
|
||||
ffmpeg: 'true'
|
||||
image-type: 'core'
|
||||
runs-on: 'ubuntu-latest'
|
||||
- build-type: 'sycl_f16'
|
||||
platforms: 'linux/amd64'
|
||||
tag-latest: 'false'
|
||||
tag-suffix: 'sycl-f16-core'
|
||||
ffmpeg: 'false'
|
||||
image-type: 'core'
|
||||
runs-on: 'arc-runner-set'
|
||||
- build-type: 'sycl_f32'
|
||||
platforms: 'linux/amd64'
|
||||
tag-latest: 'false'
|
||||
tag-suffix: 'sycl-f32-core'
|
||||
ffmpeg: 'false'
|
||||
image-type: 'core'
|
||||
runs-on: 'arc-runner-set'
|
||||
- build-type: 'sycl_f16'
|
||||
platforms: 'linux/amd64'
|
||||
tag-latest: 'false'
|
||||
tag-suffix: 'sycl-f16-ffmpeg-core'
|
||||
ffmpeg: 'true'
|
||||
image-type: 'core'
|
||||
runs-on: 'arc-runner-set'
|
||||
- build-type: 'sycl_f32'
|
||||
platforms: 'linux/amd64'
|
||||
tag-latest: 'false'
|
||||
tag-suffix: 'sycl-f32-ffmpeg-core'
|
||||
ffmpeg: 'true'
|
||||
image-type: 'core'
|
||||
runs-on: 'arc-runner-set'
|
||||
- build-type: 'cublas'
|
||||
cuda-major-version: "11"
|
||||
cuda-minor-version: "7"
|
||||
|
||||
@ -2,7 +2,6 @@ ARG GO_VERSION=1.21-bullseye
|
||||
ARG IMAGE_TYPE=extras
|
||||
# extras or core
|
||||
|
||||
|
||||
FROM golang:$GO_VERSION as requirements-core
|
||||
|
||||
ARG BUILD_TYPE
|
||||
@ -38,6 +37,14 @@ RUN if [ "${BUILD_TYPE}" = "cublas" ]; then \
|
||||
apt-get update && \
|
||||
apt-get install -y cuda-nvcc-${CUDA_MAJOR_VERSION}-${CUDA_MINOR_VERSION} libcublas-dev-${CUDA_MAJOR_VERSION}-${CUDA_MINOR_VERSION} libcusparse-dev-${CUDA_MAJOR_VERSION}-${CUDA_MINOR_VERSION} libcusolver-dev-${CUDA_MAJOR_VERSION}-${CUDA_MINOR_VERSION} && apt-get clean \
|
||||
; fi
|
||||
|
||||
# oneapi requirements
|
||||
RUN if [ "${BUILD_TYPE}" = "sycl_f16" ] || [ "${BUILD_TYPE}" = "sycl_f32" ]; then \
|
||||
wget -q https://registrationcenter-download.intel.com/akdlm/IRC_NAS/163da6e4-56eb-4948-aba3-debcec61c064/l_BaseKit_p_2024.0.1.46_offline.sh && \
|
||||
sh ./l_BaseKit_p_2024.0.1.46_offline.sh -a -s --eula accept && \
|
||||
rm -rf l_BaseKit_p_2024.0.1.46_offline.sh \
|
||||
; fi
|
||||
|
||||
ENV PATH /usr/local/cuda/bin:${PATH}
|
||||
|
||||
# OpenBLAS requirements and stable diffusion
|
||||
|
||||
2
Makefile
2
Makefile
@ -8,7 +8,7 @@ GOLLAMA_VERSION?=aeba71ee842819da681ea537e78846dc75949ac0
|
||||
|
||||
GOLLAMA_STABLE_VERSION?=50cee7712066d9e38306eccadcfbb44ea87df4b7
|
||||
|
||||
CPPLLAMA_VERSION?=e0085fdf7c758f0bc2746fc106fb29dd9df959de
|
||||
CPPLLAMA_VERSION?=1cfb5372cf5707c8ec6dde7c874f4a44a6c4c915
|
||||
|
||||
# gpt4all version
|
||||
GPT4ALL_REPO?=https://github.com/nomic-ai/gpt4all
|
||||
|
||||
@ -70,7 +70,7 @@ add_library(hw_grpc_proto
|
||||
${hw_proto_srcs}
|
||||
${hw_proto_hdrs} )
|
||||
|
||||
add_executable(${TARGET} grpc-server.cpp json.hpp )
|
||||
add_executable(${TARGET} grpc-server.cpp utils.hpp json.hpp)
|
||||
target_link_libraries(${TARGET} PRIVATE common llama myclip ${CMAKE_THREAD_LIBS_INIT} absl::flags hw_grpc_proto
|
||||
absl::flags_parse
|
||||
gRPC::${_REFLECTION}
|
||||
|
||||
@ -3,6 +3,7 @@ LLAMA_VERSION?=
|
||||
|
||||
CMAKE_ARGS?=
|
||||
BUILD_TYPE?=
|
||||
ONEAPI_VARS?=/opt/intel/oneapi/setvars.sh
|
||||
|
||||
# If build type is cublas, then we set -DLLAMA_CUBLAS=ON to CMAKE_ARGS automatically
|
||||
ifeq ($(BUILD_TYPE),cublas)
|
||||
@ -19,6 +20,14 @@ else ifeq ($(BUILD_TYPE),hipblas)
|
||||
CMAKE_ARGS+=-DLLAMA_HIPBLAS=ON
|
||||
endif
|
||||
|
||||
ifeq ($(BUILD_TYPE),sycl_f16)
|
||||
CMAKE_ARGS+=-DLLAMA_SYCL=ON -DCMAKE_C_COMPILER=icx -DCMAKE_CXX_COMPILER=icpx -DLLAMA_SYCL_F16=ON
|
||||
endif
|
||||
|
||||
ifeq ($(BUILD_TYPE),sycl_f32)
|
||||
CMAKE_ARGS+=-DLLAMA_SYCL=ON -DCMAKE_C_COMPILER=icx -DCMAKE_CXX_COMPILER=icpx
|
||||
endif
|
||||
|
||||
llama.cpp:
|
||||
git clone --recurse-submodules https://github.com/ggerganov/llama.cpp llama.cpp
|
||||
if [ -z "$(LLAMA_VERSION)" ]; then \
|
||||
@ -31,6 +40,7 @@ llama.cpp/examples/grpc-server:
|
||||
cp -r $(abspath ./)/CMakeLists.txt llama.cpp/examples/grpc-server/
|
||||
cp -r $(abspath ./)/grpc-server.cpp llama.cpp/examples/grpc-server/
|
||||
cp -rfv $(abspath ./)/json.hpp llama.cpp/examples/grpc-server/
|
||||
cp -rfv $(abspath ./)/utils.hpp llama.cpp/examples/grpc-server/
|
||||
echo "add_subdirectory(grpc-server)" >> llama.cpp/examples/CMakeLists.txt
|
||||
## XXX: In some versions of CMake clip wasn't being built before llama.
|
||||
## This is an hack for now, but it should be fixed in the future.
|
||||
@ -49,5 +59,10 @@ clean:
|
||||
rm -rf grpc-server
|
||||
|
||||
grpc-server: llama.cpp llama.cpp/examples/grpc-server
|
||||
ifneq (,$(findstring sycl,$(BUILD_TYPE)))
|
||||
bash -c "source $(ONEAPI_VARS); \
|
||||
cd llama.cpp && mkdir -p build && cd build && cmake .. $(CMAKE_ARGS) && cmake --build . --config Release"
|
||||
else
|
||||
cd llama.cpp && mkdir -p build && cd build && cmake .. $(CMAKE_ARGS) && cmake --build . --config Release
|
||||
endif
|
||||
cp llama.cpp/build/bin/grpc-server .
|
||||
File diff suppressed because it is too large
Load Diff
510
backend/cpp/llama/utils.hpp
Normal file
510
backend/cpp/llama/utils.hpp
Normal file
@ -0,0 +1,510 @@
|
||||
// https://github.com/ggerganov/llama.cpp/blob/master/examples/server/utils.hpp
|
||||
|
||||
#pragma once
|
||||
|
||||
#include <string>
|
||||
#include <vector>
|
||||
#include <set>
|
||||
#include <mutex>
|
||||
#include <condition_variable>
|
||||
#include <unordered_map>
|
||||
|
||||
#include "json.hpp"
|
||||
|
||||
#include "../llava/clip.h"
|
||||
|
||||
using json = nlohmann::json;
|
||||
|
||||
extern bool server_verbose;
|
||||
|
||||
#ifndef SERVER_VERBOSE
|
||||
#define SERVER_VERBOSE 1
|
||||
#endif
|
||||
|
||||
#if SERVER_VERBOSE != 1
|
||||
#define LOG_VERBOSE(MSG, ...)
|
||||
#else
|
||||
#define LOG_VERBOSE(MSG, ...) \
|
||||
do \
|
||||
{ \
|
||||
if (server_verbose) \
|
||||
{ \
|
||||
server_log("VERBOSE", __func__, __LINE__, MSG, __VA_ARGS__); \
|
||||
} \
|
||||
} while (0)
|
||||
#endif
|
||||
|
||||
#define LOG_ERROR( MSG, ...) server_log("ERROR", __func__, __LINE__, MSG, __VA_ARGS__)
|
||||
#define LOG_WARNING(MSG, ...) server_log("WARNING", __func__, __LINE__, MSG, __VA_ARGS__)
|
||||
#define LOG_INFO( MSG, ...) server_log("INFO", __func__, __LINE__, MSG, __VA_ARGS__)
|
||||
|
||||
//
|
||||
// parallel
|
||||
//
|
||||
|
||||
enum server_state {
|
||||
SERVER_STATE_LOADING_MODEL, // Server is starting up, model not fully loaded yet
|
||||
SERVER_STATE_READY, // Server is ready and model is loaded
|
||||
SERVER_STATE_ERROR // An error occurred, load_model failed
|
||||
};
|
||||
|
||||
enum task_type {
|
||||
TASK_TYPE_COMPLETION,
|
||||
TASK_TYPE_CANCEL,
|
||||
TASK_TYPE_NEXT_RESPONSE
|
||||
};
|
||||
|
||||
struct task_server {
|
||||
int id = -1; // to be filled by llama_server_queue
|
||||
int target_id;
|
||||
task_type type;
|
||||
json data;
|
||||
bool infill_mode = false;
|
||||
bool embedding_mode = false;
|
||||
int multitask_id = -1;
|
||||
};
|
||||
|
||||
struct task_result {
|
||||
int id;
|
||||
int multitask_id = -1;
|
||||
bool stop;
|
||||
bool error;
|
||||
json result_json;
|
||||
};
|
||||
|
||||
struct task_multi {
|
||||
int id;
|
||||
std::set<int> subtasks_remaining{};
|
||||
std::vector<task_result> results{};
|
||||
};
|
||||
|
||||
// TODO: can become bool if we can't find use of more states
|
||||
enum slot_state
|
||||
{
|
||||
IDLE,
|
||||
PROCESSING,
|
||||
};
|
||||
|
||||
enum slot_command
|
||||
{
|
||||
NONE,
|
||||
LOAD_PROMPT,
|
||||
RELEASE,
|
||||
};
|
||||
|
||||
struct slot_params
|
||||
{
|
||||
bool stream = true;
|
||||
bool cache_prompt = false; // remember the prompt to avoid reprocessing all prompt
|
||||
|
||||
uint32_t seed = -1; // RNG seed
|
||||
int32_t n_keep = 0; // number of tokens to keep from initial prompt
|
||||
int32_t n_predict = -1; // new tokens to predict
|
||||
|
||||
std::vector<std::string> antiprompt;
|
||||
|
||||
json input_prefix;
|
||||
json input_suffix;
|
||||
};
|
||||
|
||||
struct slot_image
|
||||
{
|
||||
int32_t id;
|
||||
|
||||
bool request_encode_image = false;
|
||||
float * image_embedding = nullptr;
|
||||
int32_t image_tokens = 0;
|
||||
|
||||
clip_image_u8 * img_data;
|
||||
|
||||
std::string prefix_prompt; // before of this image
|
||||
};
|
||||
|
||||
// completion token output with probabilities
|
||||
struct completion_token_output
|
||||
{
|
||||
struct token_prob
|
||||
{
|
||||
llama_token tok;
|
||||
float prob;
|
||||
};
|
||||
|
||||
std::vector<token_prob> probs;
|
||||
llama_token tok;
|
||||
std::string text_to_send;
|
||||
};
|
||||
|
||||
static inline void server_log(const char *level, const char *function, int line,
|
||||
const char *message, const nlohmann::ordered_json &extra)
|
||||
{
|
||||
nlohmann::ordered_json log
|
||||
{
|
||||
{"timestamp", time(nullptr)},
|
||||
{"level", level},
|
||||
{"function", function},
|
||||
{"line", line},
|
||||
{"message", message},
|
||||
};
|
||||
|
||||
if (!extra.empty())
|
||||
{
|
||||
log.merge_patch(extra);
|
||||
}
|
||||
|
||||
const std::string str = log.dump(-1, ' ', false, json::error_handler_t::replace);
|
||||
printf("%.*s\n", (int)str.size(), str.data());
|
||||
fflush(stdout);
|
||||
}
|
||||
|
||||
//
|
||||
// server utils
|
||||
//
|
||||
|
||||
template <typename T>
|
||||
static T json_value(const json &body, const std::string &key, const T &default_value)
|
||||
{
|
||||
// Fallback null to default value
|
||||
return body.contains(key) && !body.at(key).is_null()
|
||||
? body.value(key, default_value)
|
||||
: default_value;
|
||||
}
|
||||
|
||||
inline std::string format_chatml(std::vector<json> messages)
|
||||
{
|
||||
std::ostringstream chatml_msgs;
|
||||
|
||||
for (auto it = messages.begin(); it != messages.end(); ++it) {
|
||||
chatml_msgs << "<|im_start|>"
|
||||
<< json_value(*it, "role", std::string("user")) << '\n';
|
||||
chatml_msgs << json_value(*it, "content", std::string(""))
|
||||
<< "<|im_end|>\n";
|
||||
}
|
||||
|
||||
chatml_msgs << "<|im_start|>assistant" << '\n';
|
||||
|
||||
return chatml_msgs.str();
|
||||
}
|
||||
|
||||
//
|
||||
// work queue utils
|
||||
//
|
||||
|
||||
struct llama_server_queue {
|
||||
int id = 0;
|
||||
std::mutex mutex_tasks;
|
||||
// queues
|
||||
std::vector<task_server> queue_tasks;
|
||||
std::vector<task_server> queue_tasks_deferred;
|
||||
std::vector<task_multi> queue_multitasks;
|
||||
std::condition_variable condition_tasks;
|
||||
// callback functions
|
||||
std::function<void(task_server&)> callback_new_task;
|
||||
std::function<void(task_multi&)> callback_finish_multitask;
|
||||
std::function<void(void)> callback_all_task_finished;
|
||||
|
||||
// Add a new task to the end of the queue
|
||||
int post(task_server task) {
|
||||
std::unique_lock<std::mutex> lock(mutex_tasks);
|
||||
if (task.id == -1) {
|
||||
task.id = id++;
|
||||
}
|
||||
queue_tasks.push_back(std::move(task));
|
||||
condition_tasks.notify_one();
|
||||
return task.id;
|
||||
}
|
||||
|
||||
// Add a new task, but defer until one slot is available
|
||||
void defer(task_server task) {
|
||||
std::unique_lock<std::mutex> lock(mutex_tasks);
|
||||
queue_tasks_deferred.push_back(std::move(task));
|
||||
}
|
||||
|
||||
// Get the next id for creating anew task
|
||||
int get_new_id() {
|
||||
std::unique_lock<std::mutex> lock(mutex_tasks);
|
||||
return id++;
|
||||
}
|
||||
|
||||
// Register function to process a new task
|
||||
void on_new_task(std::function<void(task_server&)> callback) {
|
||||
callback_new_task = callback;
|
||||
}
|
||||
|
||||
// Register function to process a multitask
|
||||
void on_finish_multitask(std::function<void(task_multi&)> callback) {
|
||||
callback_finish_multitask = callback;
|
||||
}
|
||||
|
||||
// Register the function to be called when the batch of tasks is finished
|
||||
void on_all_tasks_finished(std::function<void(void)> callback) {
|
||||
callback_all_task_finished = callback;
|
||||
}
|
||||
|
||||
// Call when the state of one slot is changed
|
||||
void notify_slot_changed() {
|
||||
// move deferred tasks back to main loop
|
||||
std::unique_lock<std::mutex> lock(mutex_tasks);
|
||||
for (auto & task : queue_tasks_deferred) {
|
||||
queue_tasks.push_back(std::move(task));
|
||||
}
|
||||
queue_tasks_deferred.clear();
|
||||
}
|
||||
|
||||
// Start the main loop. This call is blocking
|
||||
[[noreturn]]
|
||||
void start_loop() {
|
||||
while (true) {
|
||||
// new task arrived
|
||||
LOG_VERBOSE("have new task", {});
|
||||
{
|
||||
while (true)
|
||||
{
|
||||
std::unique_lock<std::mutex> lock(mutex_tasks);
|
||||
if (queue_tasks.empty()) {
|
||||
lock.unlock();
|
||||
break;
|
||||
}
|
||||
task_server task = queue_tasks.front();
|
||||
queue_tasks.erase(queue_tasks.begin());
|
||||
lock.unlock();
|
||||
LOG_VERBOSE("callback_new_task", {});
|
||||
callback_new_task(task);
|
||||
}
|
||||
LOG_VERBOSE("callback_all_task_finished", {});
|
||||
// process and update all the multitasks
|
||||
auto queue_iterator = queue_multitasks.begin();
|
||||
while (queue_iterator != queue_multitasks.end())
|
||||
{
|
||||
if (queue_iterator->subtasks_remaining.empty())
|
||||
{
|
||||
// all subtasks done == multitask is done
|
||||
task_multi current_multitask = *queue_iterator;
|
||||
callback_finish_multitask(current_multitask);
|
||||
// remove this multitask
|
||||
queue_iterator = queue_multitasks.erase(queue_iterator);
|
||||
}
|
||||
else
|
||||
{
|
||||
++queue_iterator;
|
||||
}
|
||||
}
|
||||
// all tasks in the current loop is finished
|
||||
callback_all_task_finished();
|
||||
}
|
||||
LOG_VERBOSE("wait for new task", {});
|
||||
// wait for new task
|
||||
{
|
||||
std::unique_lock<std::mutex> lock(mutex_tasks);
|
||||
if (queue_tasks.empty()) {
|
||||
condition_tasks.wait(lock, [&]{
|
||||
return !queue_tasks.empty();
|
||||
});
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
//
|
||||
// functions to manage multitasks
|
||||
//
|
||||
|
||||
// add a multitask by specifying the id of all subtask (subtask is a task_server)
|
||||
void add_multitask(int multitask_id, std::vector<int>& sub_ids)
|
||||
{
|
||||
std::lock_guard<std::mutex> lock(mutex_tasks);
|
||||
task_multi multi;
|
||||
multi.id = multitask_id;
|
||||
std::copy(sub_ids.begin(), sub_ids.end(), std::inserter(multi.subtasks_remaining, multi.subtasks_remaining.end()));
|
||||
queue_multitasks.push_back(multi);
|
||||
}
|
||||
|
||||
// updatethe remaining subtasks, while appending results to multitask
|
||||
void update_multitask(int multitask_id, int subtask_id, task_result& result)
|
||||
{
|
||||
std::lock_guard<std::mutex> lock(mutex_tasks);
|
||||
for (auto& multitask : queue_multitasks)
|
||||
{
|
||||
if (multitask.id == multitask_id)
|
||||
{
|
||||
multitask.subtasks_remaining.erase(subtask_id);
|
||||
multitask.results.push_back(result);
|
||||
}
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
struct llama_server_response {
|
||||
typedef std::function<void(int, int, task_result&)> callback_multitask_t;
|
||||
callback_multitask_t callback_update_multitask;
|
||||
// for keeping track of all tasks waiting for the result
|
||||
std::set<int> waiting_task_ids;
|
||||
// the main result queue
|
||||
std::vector<task_result> queue_results;
|
||||
std::mutex mutex_results;
|
||||
std::condition_variable condition_results;
|
||||
|
||||
void add_waiting_task_id(int task_id) {
|
||||
std::unique_lock<std::mutex> lock(mutex_results);
|
||||
waiting_task_ids.insert(task_id);
|
||||
}
|
||||
|
||||
void remove_waiting_task_id(int task_id) {
|
||||
std::unique_lock<std::mutex> lock(mutex_results);
|
||||
waiting_task_ids.erase(task_id);
|
||||
}
|
||||
|
||||
// This function blocks the thread until there is a response for this task_id
|
||||
task_result recv(int task_id) {
|
||||
while (true)
|
||||
{
|
||||
std::unique_lock<std::mutex> lock(mutex_results);
|
||||
condition_results.wait(lock, [&]{
|
||||
return !queue_results.empty();
|
||||
});
|
||||
LOG_VERBOSE("condition_results unblock", {});
|
||||
|
||||
for (int i = 0; i < (int) queue_results.size(); i++)
|
||||
{
|
||||
if (queue_results[i].id == task_id)
|
||||
{
|
||||
assert(queue_results[i].multitask_id == -1);
|
||||
task_result res = queue_results[i];
|
||||
queue_results.erase(queue_results.begin() + i);
|
||||
return res;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// should never reach here
|
||||
}
|
||||
|
||||
// Register the function to update multitask
|
||||
void on_multitask_update(callback_multitask_t callback) {
|
||||
callback_update_multitask = callback;
|
||||
}
|
||||
|
||||
// Send a new result to a waiting task_id
|
||||
void send(task_result result) {
|
||||
std::unique_lock<std::mutex> lock(mutex_results);
|
||||
LOG_VERBOSE("send new result", {});
|
||||
for (auto& task_id : waiting_task_ids) {
|
||||
// LOG_TEE("waiting task id %i \n", task_id);
|
||||
// for now, tasks that have associated parent multitasks just get erased once multitask picks up the result
|
||||
if (result.multitask_id == task_id)
|
||||
{
|
||||
LOG_VERBOSE("callback_update_multitask", {});
|
||||
callback_update_multitask(task_id, result.id, result);
|
||||
continue;
|
||||
}
|
||||
|
||||
if (result.id == task_id)
|
||||
{
|
||||
LOG_VERBOSE("queue_results.push_back", {});
|
||||
queue_results.push_back(result);
|
||||
condition_results.notify_one();
|
||||
return;
|
||||
}
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
//
|
||||
// base64 utils (TODO: move to common in the future)
|
||||
//
|
||||
|
||||
static const std::string base64_chars =
|
||||
"ABCDEFGHIJKLMNOPQRSTUVWXYZ"
|
||||
"abcdefghijklmnopqrstuvwxyz"
|
||||
"0123456789+/";
|
||||
|
||||
static inline bool is_base64(uint8_t c)
|
||||
{
|
||||
return (isalnum(c) || (c == '+') || (c == '/'));
|
||||
}
|
||||
|
||||
static inline std::vector<uint8_t> base64_decode(const std::string & encoded_string)
|
||||
{
|
||||
int i = 0;
|
||||
int j = 0;
|
||||
int in_ = 0;
|
||||
|
||||
int in_len = encoded_string.size();
|
||||
|
||||
uint8_t char_array_4[4];
|
||||
uint8_t char_array_3[3];
|
||||
|
||||
std::vector<uint8_t> ret;
|
||||
|
||||
while (in_len-- && (encoded_string[in_] != '=') && is_base64(encoded_string[in_]))
|
||||
{
|
||||
char_array_4[i++] = encoded_string[in_]; in_++;
|
||||
if (i == 4)
|
||||
{
|
||||
for (i = 0; i <4; i++)
|
||||
{
|
||||
char_array_4[i] = base64_chars.find(char_array_4[i]);
|
||||
}
|
||||
|
||||
char_array_3[0] = ((char_array_4[0] ) << 2) + ((char_array_4[1] & 0x30) >> 4);
|
||||
char_array_3[1] = ((char_array_4[1] & 0xf) << 4) + ((char_array_4[2] & 0x3c) >> 2);
|
||||
char_array_3[2] = ((char_array_4[2] & 0x3) << 6) + char_array_4[3];
|
||||
|
||||
for (i = 0; (i < 3); i++)
|
||||
{
|
||||
ret.push_back(char_array_3[i]);
|
||||
}
|
||||
i = 0;
|
||||
}
|
||||
}
|
||||
|
||||
if (i)
|
||||
{
|
||||
for (j = i; j <4; j++)
|
||||
{
|
||||
char_array_4[j] = 0;
|
||||
}
|
||||
|
||||
for (j = 0; j <4; j++)
|
||||
{
|
||||
char_array_4[j] = base64_chars.find(char_array_4[j]);
|
||||
}
|
||||
|
||||
char_array_3[0] = ((char_array_4[0] ) << 2) + ((char_array_4[1] & 0x30) >> 4);
|
||||
char_array_3[1] = ((char_array_4[1] & 0xf) << 4) + ((char_array_4[2] & 0x3c) >> 2);
|
||||
char_array_3[2] = ((char_array_4[2] & 0x3) << 6) + char_array_4[3];
|
||||
|
||||
for (j = 0; (j < i - 1); j++)
|
||||
{
|
||||
ret.push_back(char_array_3[j]);
|
||||
}
|
||||
}
|
||||
|
||||
return ret;
|
||||
}
|
||||
|
||||
//
|
||||
// random string / id
|
||||
//
|
||||
|
||||
static std::string random_string()
|
||||
{
|
||||
static const std::string str("0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz");
|
||||
|
||||
std::random_device rd;
|
||||
std::mt19937 generator(rd());
|
||||
|
||||
std::string result(32, ' ');
|
||||
|
||||
for (int i = 0; i < 32; ++i) {
|
||||
result[i] = str[generator() % str.size()];
|
||||
}
|
||||
|
||||
return result;
|
||||
}
|
||||
|
||||
static std::string gen_chatcmplid()
|
||||
{
|
||||
std::stringstream chatcmplid;
|
||||
chatcmplid << "chatcmpl-" << random_string();
|
||||
return chatcmplid.str();
|
||||
}
|
||||
@ -15,9 +15,45 @@ This section contains instruction on how to use LocalAI with GPU acceleration.
|
||||
For accelleration for AMD or Metal HW there are no specific container images, see the [build]({{%relref "docs/getting-started/build#Acceleration" %}})
|
||||
{{% /alert %}}
|
||||
|
||||
### CUDA(NVIDIA) acceleration
|
||||
|
||||
#### Requirements
|
||||
## Model configuration
|
||||
|
||||
Depending on the model architecture and backend used, there might be different ways to enable GPU acceleration. It is required to configure the model you intend to use with a YAML config file. For example, for `llama.cpp` workloads a configuration file might look like this (where `gpu_layers` is the number of layers to offload to the GPU):
|
||||
|
||||
```yaml
|
||||
name: my-model-name
|
||||
# Default model parameters
|
||||
parameters:
|
||||
# Relative to the models path
|
||||
model: llama.cpp-model.ggmlv3.q5_K_M.bin
|
||||
|
||||
context_size: 1024
|
||||
threads: 1
|
||||
|
||||
f16: true # enable with GPU acceleration
|
||||
gpu_layers: 22 # GPU Layers (only used when built with cublas)
|
||||
|
||||
```
|
||||
|
||||
For diffusers instead, it might look like this instead:
|
||||
|
||||
```yaml
|
||||
name: stablediffusion
|
||||
parameters:
|
||||
model: toonyou_beta6.safetensors
|
||||
backend: diffusers
|
||||
step: 30
|
||||
f16: true
|
||||
diffusers:
|
||||
pipeline_type: StableDiffusionPipeline
|
||||
cuda: true
|
||||
enable_parameters: "negative_prompt,num_inference_steps,clip_skip"
|
||||
scheduler_type: "k_dpmpp_sde"
|
||||
```
|
||||
|
||||
## CUDA(NVIDIA) acceleration
|
||||
|
||||
### Requirements
|
||||
|
||||
Requirement: nvidia-container-toolkit (installation instructions [1](https://www.server-world.info/en/note?os=Ubuntu_22.04&p=nvidia&f=2) [2](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html))
|
||||
|
||||
@ -74,37 +110,21 @@ llama_model_load_internal: total VRAM used: 1598 MB
|
||||
llama_init_from_file: kv self size = 512.00 MB
|
||||
```
|
||||
|
||||
#### Model configuration
|
||||
## Intel acceleration (sycl)
|
||||
|
||||
Depending on the model architecture and backend used, there might be different ways to enable GPU acceleration. It is required to configure the model you intend to use with a YAML config file. For example, for `llama.cpp` workloads a configuration file might look like this (where `gpu_layers` is the number of layers to offload to the GPU):
|
||||
#### Requirements
|
||||
|
||||
```yaml
|
||||
name: my-model-name
|
||||
# Default model parameters
|
||||
parameters:
|
||||
# Relative to the models path
|
||||
model: llama.cpp-model.ggmlv3.q5_K_M.bin
|
||||
Requirement: [Intel oneAPI Base Toolkit](https://software.intel.com/content/www/us/en/develop/tools/oneapi/base-toolkit/download.html)
|
||||
|
||||
context_size: 1024
|
||||
threads: 1
|
||||
To use SYCL, use the images with the `sycl-f16` or `sycl-f32` tag, for example `{{< version >}}-sycl-f32-core`, `{{< version >}}-sycl-f16-ffmpeg-core`, ...
|
||||
|
||||
f16: true # enable with GPU acceleration
|
||||
gpu_layers: 22 # GPU Layers (only used when built with cublas)
|
||||
The image list is on [quay](https://quay.io/repository/go-skynet/local-ai?tab=tags).
|
||||
|
||||
### Notes
|
||||
|
||||
In addition to the commands to run LocalAI normally, you need to specify `--device /dev/dri` to docker, for example:
|
||||
|
||||
```bash
|
||||
docker run --rm -ti --device /dev/dri -p 8080:8080 -e DEBUG=true -e MODELS_PATH=/models -e THREADS=1 -v $PWD/models:/models quay.io/go-skynet/local-ai:{{< version >}}-sycl-f16-ffmpeg-core
|
||||
```
|
||||
|
||||
For diffusers instead, it might look like this instead:
|
||||
|
||||
```yaml
|
||||
name: stablediffusion
|
||||
parameters:
|
||||
model: toonyou_beta6.safetensors
|
||||
backend: diffusers
|
||||
step: 30
|
||||
f16: true
|
||||
diffusers:
|
||||
pipeline_type: StableDiffusionPipeline
|
||||
cuda: true
|
||||
enable_parameters: "negative_prompt,num_inference_steps,clip_skip"
|
||||
scheduler_type: "k_dpmpp_sde"
|
||||
```
|
||||
@ -83,7 +83,7 @@ Here is the list of the variables available that can be used to customize the bu
|
||||
|
||||
| Variable | Default | Description |
|
||||
| ---------------------| ------- | ----------- |
|
||||
| `BUILD_TYPE` | None | Build type. Available: `cublas`, `openblas`, `clblas`, `metal`,`hipblas` |
|
||||
| `BUILD_TYPE` | None | Build type. Available: `cublas`, `openblas`, `clblas`, `metal`,`hipblas`, `sycl_f16`, `sycl_f32` |
|
||||
| `GO_TAGS` | `tts stablediffusion` | Go tags. Available: `stablediffusion`, `tts`, `tinydream` |
|
||||
| `CLBLAST_DIR` | | Specify a CLBlast directory |
|
||||
| `CUDA_LIBPATH` | | Specify a CUDA library path |
|
||||
@ -225,6 +225,17 @@ make BUILD_TYPE=clblas build
|
||||
|
||||
To specify a clblast dir set: `CLBLAST_DIR`
|
||||
|
||||
#### Intel GPU acceleration
|
||||
|
||||
Intel GPU acceleration is supported via SYCL.
|
||||
|
||||
Requirements: [Intel oneAPI Base Toolkit](https://www.intel.com/content/www/us/en/developer/tools/oneapi/base-toolkit-download.html) (see also [llama.cpp setup installations instructions](https://github.com/ggerganov/llama.cpp/blob/d71ac90985854b0905e1abba778e407e17f9f887/README-sycl.md?plain=1#L56))
|
||||
|
||||
```
|
||||
make BUILD_TYPE=sycl_f16 build # for float16
|
||||
make BUILD_TYPE=sycl_f32 build # for float32
|
||||
```
|
||||
|
||||
#### Metal (Apple Silicon)
|
||||
|
||||
```
|
||||
|
||||
@ -74,14 +74,6 @@ Note that this started just as a fun weekend project by [mudler](https://github.
|
||||
- 🖼️ [Download Models directly from Huggingface ](https://localai.io/models/)
|
||||
- 🆕 [Vision API](https://localai.io/features/gpt-vision/)
|
||||
|
||||
## How does it work?
|
||||
|
||||
LocalAI is an API written in Go that serves as an OpenAI shim, enabling software already developed with OpenAI SDKs to seamlessly integrate with LocalAI. It can be effortlessly implemented as a substitute, even on consumer-grade hardware. This capability is achieved by employing various C++ backends, including [ggml](https://github.com/ggerganov/ggml), to perform inference on LLMs using both CPU and, if desired, GPU. Internally LocalAI backends are just gRPC server, indeed you can specify and build your own gRPC server and extend LocalAI in runtime as well. It is possible to specify external gRPC server and/or binaries that LocalAI will manage internally.
|
||||
|
||||
LocalAI uses a mixture of backends written in various languages (C++, Golang, Python, ...). You can check [the model compatibility table]({{%relref "docs/reference/compatibility-table" %}}) to learn about all the components of LocalAI.
|
||||
|
||||
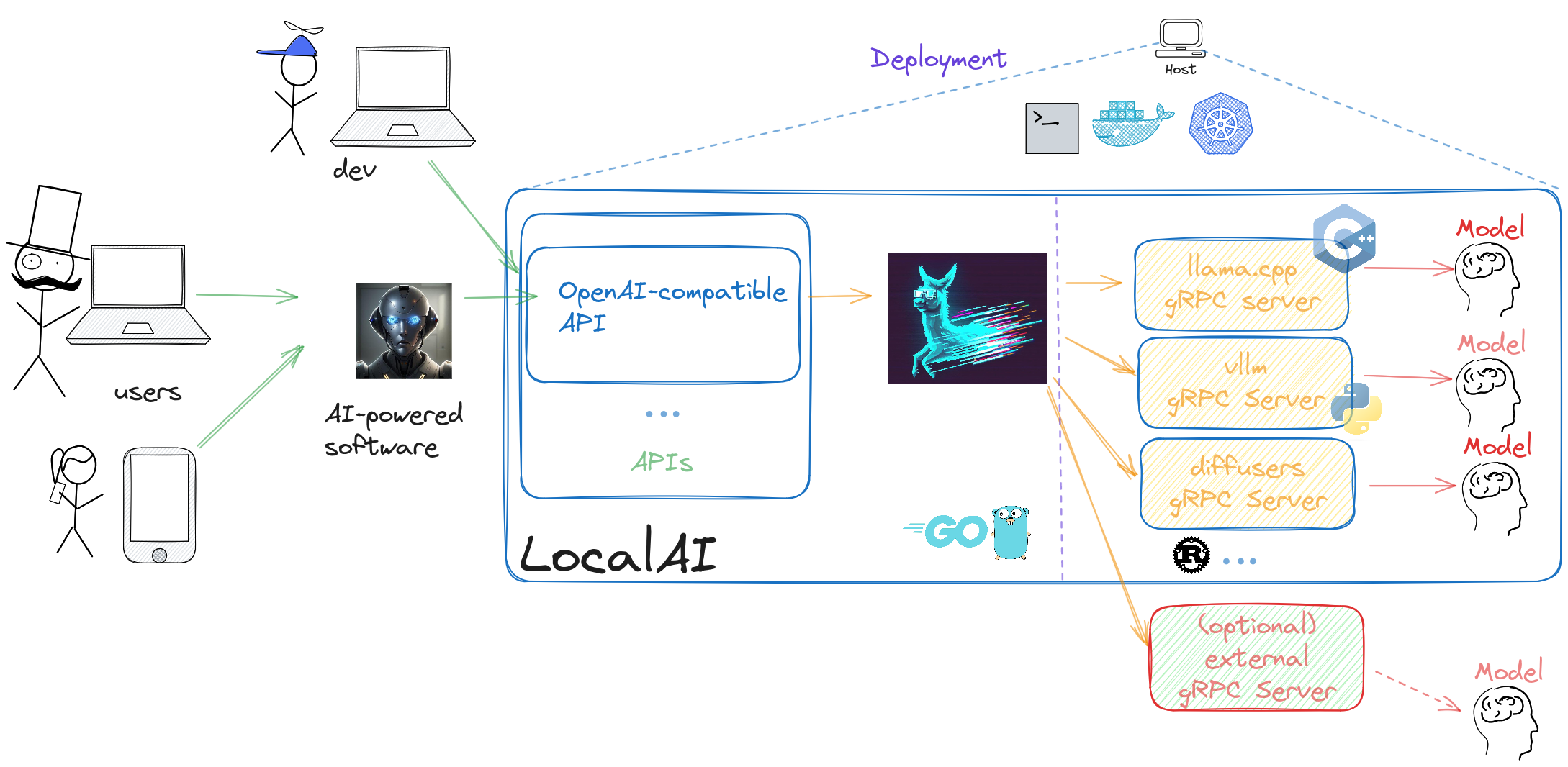
|
||||
|
||||
## Contribute and help
|
||||
|
||||
To help the project you can:
|
||||
@ -114,20 +106,6 @@ LocalAI couldn't have been built without the help of great software already avai
|
||||
- https://github.com/rhasspy/piper
|
||||
- https://github.com/cmp-nct/ggllm.cpp
|
||||
|
||||
|
||||
|
||||
## Backstory
|
||||
|
||||
As much as typical open source projects starts, I, [mudler](https://github.com/mudler/), was fiddling around with [llama.cpp](https://github.com/ggerganov/llama.cpp) over my long nights and wanted to have a way to call it from `go`, as I am a Golang developer and use it extensively. So I've created `LocalAI` (or what was initially known as `llama-cli`) and added an API to it.
|
||||
|
||||
But guess what? The more I dived into this rabbit hole, the more I realized that I had stumbled upon something big. With all the fantastic C++ projects floating around the community, it dawned on me that I could piece them together to create a full-fledged OpenAI replacement. So, ta-da! LocalAI was born, and it quickly overshadowed its humble origins.
|
||||
|
||||
Now, why did I choose to go with C++ bindings, you ask? Well, I wanted to keep LocalAI snappy and lightweight, allowing it to run like a champ on any system and avoid any Golang penalties of the GC, and, most importantly built on shoulders of giants like `llama.cpp`. Go is good at backends and API and is easy to maintain. And hey, don't forget that I'm all about sharing the love. That's why I made LocalAI MIT licensed, so everyone can hop on board and benefit from it.
|
||||
|
||||
As if that wasn't exciting enough, as the project gained traction, [mkellerman](https://github.com/mkellerman) and [Aisuko](https://github.com/Aisuko) jumped in to lend a hand. mkellerman helped set up some killer examples, while Aisuko is becoming our community maestro. The community now is growing even more with new contributors and users, and I couldn't be happier about it!
|
||||
|
||||
Oh, and let's not forget the real MVP here—[llama.cpp](https://github.com/ggerganov/llama.cpp). Without this extraordinary piece of software, LocalAI wouldn't even exist. So, a big shoutout to the community for making this magic happen!
|
||||
|
||||
## 🤗 Contributors
|
||||
|
||||
This is a community project, a special thanks to our contributors! 🤗
|
||||
|
||||
25
docs/content/docs/reference/architecture.md
Normal file
25
docs/content/docs/reference/architecture.md
Normal file
@ -0,0 +1,25 @@
|
||||
|
||||
+++
|
||||
disableToc = false
|
||||
title = "Architecture"
|
||||
weight = 25
|
||||
+++
|
||||
|
||||
LocalAI is an API written in Go that serves as an OpenAI shim, enabling software already developed with OpenAI SDKs to seamlessly integrate with LocalAI. It can be effortlessly implemented as a substitute, even on consumer-grade hardware. This capability is achieved by employing various C++ backends, including [ggml](https://github.com/ggerganov/ggml), to perform inference on LLMs using both CPU and, if desired, GPU. Internally LocalAI backends are just gRPC server, indeed you can specify and build your own gRPC server and extend LocalAI in runtime as well. It is possible to specify external gRPC server and/or binaries that LocalAI will manage internally.
|
||||
|
||||
LocalAI uses a mixture of backends written in various languages (C++, Golang, Python, ...). You can check [the model compatibility table]({{%relref "docs/reference/compatibility-table" %}}) to learn about all the components of LocalAI.
|
||||
|
||||

|
||||
|
||||
|
||||
## Backstory
|
||||
|
||||
As much as typical open source projects starts, I, [mudler](https://github.com/mudler/), was fiddling around with [llama.cpp](https://github.com/ggerganov/llama.cpp) over my long nights and wanted to have a way to call it from `go`, as I am a Golang developer and use it extensively. So I've created `LocalAI` (or what was initially known as `llama-cli`) and added an API to it.
|
||||
|
||||
But guess what? The more I dived into this rabbit hole, the more I realized that I had stumbled upon something big. With all the fantastic C++ projects floating around the community, it dawned on me that I could piece them together to create a full-fledged OpenAI replacement. So, ta-da! LocalAI was born, and it quickly overshadowed its humble origins.
|
||||
|
||||
Now, why did I choose to go with C++ bindings, you ask? Well, I wanted to keep LocalAI snappy and lightweight, allowing it to run like a champ on any system and avoid any Golang penalties of the GC, and, most importantly built on shoulders of giants like `llama.cpp`. Go is good at backends and API and is easy to maintain. And hey, don't forget that I'm all about sharing the love. That's why I made LocalAI MIT licensed, so everyone can hop on board and benefit from it.
|
||||
|
||||
As if that wasn't exciting enough, as the project gained traction, [mkellerman](https://github.com/mkellerman) and [Aisuko](https://github.com/Aisuko) jumped in to lend a hand. mkellerman helped set up some killer examples, while Aisuko is becoming our community maestro. The community now is growing even more with new contributors and users, and I couldn't be happier about it!
|
||||
|
||||
Oh, and let's not forget the real MVP here—[llama.cpp](https://github.com/ggerganov/llama.cpp). Without this extraordinary piece of software, LocalAI wouldn't even exist. So, a big shoutout to the community for making this magic happen!
|
||||
@ -13,6 +13,10 @@ if [ -n "$EXTRA_BACKENDS" ]; then
|
||||
done
|
||||
fi
|
||||
|
||||
if [ -e "/opt/intel/oneapi/setvars.sh" ]; then
|
||||
source /opt/intel/oneapi/setvars.sh
|
||||
fi
|
||||
|
||||
if [ "$REBUILD" != "false" ]; then
|
||||
rm -rf ./local-ai
|
||||
make build -j${BUILD_PARALLELISM:-1}
|
||||
|
||||
Loading…
Reference in New Issue
Block a user