ℹ️ Note: This page is not actively maintained. For a more up-to-date list of scripts and extensions,
you may use the built-in tab within the web UI (Extensions->Available)
alternatively you can can also access extension index on Github at https://github.com/AUTOMATIC1111/stable-diffusion-webui-extensions
General Info
Extensions are a more convenient form of user scripts.
Extensions all exist in their own folder inside the extensions folder of webui. You can use git to install an extension like this:
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui-aesthetic-gradients extensions/aesthetic-gradients
This installs an extension from https://github.com/AUTOMATIC1111/stable-diffusion-webui-aesthetic-gradients into the extensions/aesthetic-gradients directory.
Alternatively you can just copy-paste a directory into extensions.
For developing extensions, see Developing extensions.
Security
As extensions allow the user to install and run arbitrary code, this can be used maliciously, and is disabled by default when running with options that allow remote users to connect to the server (--share or --listen) - you'll still have the UI, but trying to install anything will result in error. If you want to use those options and still be able to install extensions, use --enable-insecure-extension-access command line flag.
Extensions
MultiDiffusion with Tiled VAE
https://github.com/pkuliyi2015/multidiffusion-upscaler-for-automatic1111
MultiDiffusion
- txt2img panorama generation, as mentioned in MultiDiffusion.
- It can cooperate with ControlNet to produce wide images with control.
Panorama Example:(links not working as of Jun 2023) Before: click for the raw image After: click for the raw image
{kind=link}
{kind=link}
ControlNet Canny Output: https://github.com/pkuliyi2015/multidiffusion-upscaler-for-automatic1111/raw/docs/imgs/yourname.jpeg?raw=true
{kind=link}
Tiled Vae
The vae_optimize.py script splits the image into tiles, encodes each tile separately, and merges the results. This process allows the VAE to generate large images with limited VRAM (~10 GB for 8K images).
Using this script may allow removal of --lowvram or --medvram arguments, and thus improve image generation times.
VRAM Estimator
https://github.com/space-nuko/a1111-stable-diffusion-webui-vram-estimator
Runs txt2img, img2img, highres-fix at increasing dimensions and batch sizes until OOM, and outputs data to graph.

Dump U-Net
https://github.com/hnmr293/stable-diffusion-webui-dumpunet
View different layers, observe U-Net feature maps. Allows Image generation by giving different prompts for each block of the unet: https://note.com/kohya_ss/n/n93b7c01b0547

posex
https://github.com/hnmr293/posex
Estimated Image Generator for Pose2Image. This extension allows moving the openpose figure in 3d space.

LLuL
https://github.com/hnmr293/sd-webui-llul
Local Latent Upscaler. Target an area to selectively enhance details.
CFG-Schedule-for-Automatic1111-SD
https://github.com/guzuligo/CFG-Schedule-for-Automatic1111-SD
These 2 scripts allow for dynamic CFG control during generation steps. With the right settings, this could help get the details of high CFG without damaging the generated image even with low denoising in img2img.
See their wiki on how to use.
a1111-sd-webui-locon
https://github.com/KohakuBlueleaf/a1111-sd-webui-locon An extension for loading LoCon networks in webui.
ebsynth_utility
https://github.com/s9roll7/ebsynth_utility
Extension for creating videos using img2img and ebsynth. Output edited videos using ebsynth. Works with ControlNet extension.

LoRA Block Weight
LoRA is a powerful tool, but it is sometimes difficult to use and can affect areas that you do not want it to affect. This script allows you to set the weights block-by-block. Using this script, you may be able to get the image you want.
Used in conjunction with the XY plot, it is possible to examine the impact of each level of the hierarchy.

Included Presets:
NOT:0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
ALL:1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1
INS:1,1,1,1,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0
IND:1,0,0,0,1,1,1,1,0,0,0,0,0,0,0,0,0,0
INALL:1,1,1,1,1,1,1,1,0,0,0,0,0,0,0,0,0,0,0
MIDD:1,0,0,0,1,1,1,1,1,1,1,1,1,0,0,0,0,0
OUTD:1,0,0,0,0,0,0,0,0,1,1,1,1,1,0,0,0,0
OUTS:1,0,0,0,0,0,0,0,0,0,0,0,0,1,1,1,1,1,1,1
OUTALL:1,0,0,0,0,0,0,0,0,0,1,1,1,1,1,1,1,1,1,1
Kitchen Theme
https://github.com/canisminor1990/sd-web-ui-kitchen-theme
A custom theme for webui.

Bilingual Localization
https://github.com/journey-ad/sd-webui-bilingual-localization
Bilingual translation, no need to worry about how to find the original button. Compatible with language pack extensions, no need to re-import.

Composable LoRA
https://github.com/opparco/stable-diffusion-webui-composable-lora
Enables using AND keyword(composable diffusion) to limit LoRAs to subprompts. Useful when paired with Latent Couple extension.
Clip Interrogator
https://github.com/pharmapsychotic/clip-interrogator-ext
Clip Interrogator by pharmapsychotic ported to an extension. Features a variety of clip models and interrogate settings.

Latent-Couple
https://github.com/opparco/stable-diffusion-webui-two-shot
An extension of the built-in Composable Diffusion, allows you to determine the region of the latent space that reflects your subprompts.

OpenPose Editor
https://github.com/fkunn1326/openpose-editor
This can add multiple pose characters, detect pose from image, save to PNG, and send to controlnet extension.

SuperMerger
https://github.com/hako-mikan/sd-webui-supermerger
Merge and run without saving to drive. Sequential XY merge generations; extract and merge LoRA's, bind LoRA's to ckpt, merge block weights, and more.

Prompt Translator
https://github.com/butaixianran/Stable-Diffusion-Webui-Prompt-Translator
A integrated translator for translating prompts to English using Deepl or Baidu.

Video Loopback
https://github.com/fishslot/video_loopback_for_webui
Mine Diffusion
https://github.com/fropych/mine-diffusion
This extension converts images into blocks and creates schematics for easy importing into Minecraft using the Litematica mod.
Example: (Click to expand:)

anti-burn
https://github.com/klimaleksus/stable-diffusion-webui-anti-burn
Smoothing generated images by skipping a few very last steps and averaging together some images before them.

Embedding Merge
https://github.com/klimaleksus/stable-diffusion-webui-embedding-merge
Merging Textual Inversion embeddings at runtime from string literals.

gif2gif
The purpose of this script is to accept an animated gif as input, process frames as img2img typically would, and recombine them back into an animated gif. Intended to provide a fun, fast, gif-to-gif workflow that supports new models and methods such as Controlnet and InstructPix2Pix. Drop in a gif and go. Referenced code from prompts_from_file.
Example: (Click to expand:)

cafe-aesthetic
https://github.com/p1atdev/stable-diffusion-webui-cafe-aesthetic
Pre-trained model, determines if aesthetic/non-aesthetic, does 5 different style recognition modes, and Waifu confirmation. Also has a tab with Batch processing.

Catppuccin themes
https://github.com/catppuccin/stable-diffusion-webui
Catppuccin is a community-driven pastel theme that aims to be the middle ground between low and high contrast themes. Adds set of themes which are in compliance with catppucin guidebook.

Dynamic Thresholding
Dynamic Thresholding adds customizable dynamic thresholding to allow high CFG Scale values without the burning / 'pop art' effect.
Custom Diffusion
https://github.com/guaneec/custom-diffusion-webui
Custom Diffusion is a form of fine-tuning with TI, instead of tuning the whole model. Similar speed and memory requirements to TI and may give better results in fewer steps.
Fusion
https://github.com/ljleb/prompt-fusion-extension
Adds prompt-travel and shift-attention-like interpolations (see exts), but during/within the sampling steps. Always-on + works with existing prompt-editing syntax. Various interpolation modes. See their wiki for more info.
Example: (Click to expand:)

Pixelization
https://github.com/AUTOMATIC1111/stable-diffusion-webui-pixelization
Using pre-trained models, produce pixel art out of images in the extras tab.

Instruct-pix2pix
https://github.com/Klace/stable-diffusion-webui-instruct-pix2pix
Adds a tab for doing img2img editing with the instruct-pix2pix model. The author added the feature to webui, so this doesn't need to be used.
System Info
https://github.com/vladmandic/sd-extension-system-info
Creates a top-level System Info tab in Automatic WebUI with
Note:
- State & memory info are auto-updated every second if tab is visible
(no updates are performed when tab is not visible) - All other information is updated once upon WebUI load and
can be force refreshed if required
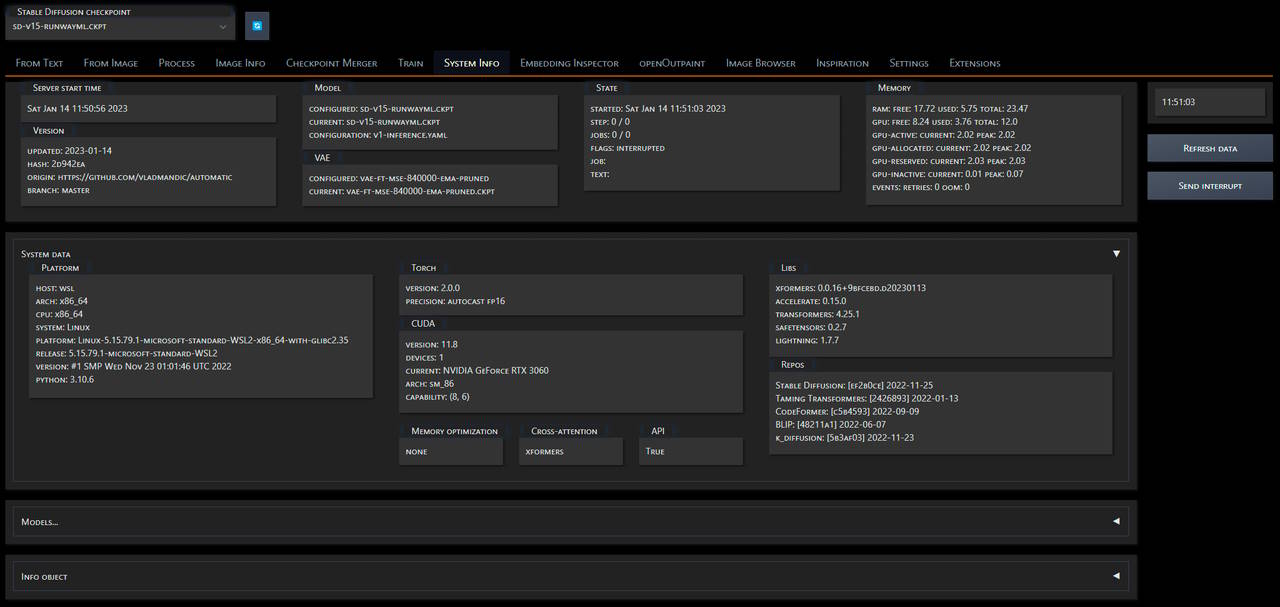
Steps Animation
https://github.com/vladmandic/sd-extension-steps-animation
Extension to create animation sequence from denoised intermediate steps
Registers a script in txt2img and img2img tabs
Creating animation has minimum impact on overall performance as it does not require separate runs
except adding overhead of saving each intermediate step as image plus few seconds to actually create movie file
Supports color and motion interpolation to achieve animation of desired duration from any number of interim steps
Resulting movie fiels are typically very small (~1MB being average) due to optimized codec settings
Example
Aesthetic Scorer
https://github.com/vladmandic/sd-extension-aesthetic-scorer
Uses existing CLiP model with an additional small pretrained to calculate perceived aesthetic score of an image
Enable or disable via Settings -> Aesthetic scorer
This is an "invisible" extension, it runs in the background before any image save and
appends score as PNG info section and/or EXIF comments field
Notes
- Configuration via Settings → Aesthetic scorer
- Extension obeys existing Move VAE and CLiP to RAM settings
- Models will be auto-downloaded upon first usage (small)
- Score values are
0..10 - Supports both
CLiP-ViT-L/14andCLiP-ViT-B/16 - Cross-platform!
Discord Rich Presence
https://github.com/kabachuha/discord-rpc-for-automatic1111-webui
Provides connection to Discord RPC, showing a fancy table in the user profile.
Promptgen
https://github.com/AUTOMATIC1111/stable-diffusion-webui-promptgen
Use transformers models to generate prompts.

haku-img
https://github.com/KohakuBlueleaf/a1111-sd-webui-haku-img
Image utils extension. Allows blending, layering, hue and color adjustments, blurring and sketch effects, and basic pixelization.

Merge Block Weighted
https://github.com/bbc-mc/sdweb-merge-block-weighted-gui
Merge models with separate rate for each 25 U-Net block (input, middle, output).

Stable Horde Worker
https://github.com/sdwebui-w-horde/sd-webui-stable-horde-worker
An unofficial Stable Horde worker bridge as a Stable Diffusion WebUI extension.
Features
This extension is still WORKING IN PROGRESS, and is not ready for production use.
- Get jobs from Stable Horde, generate images and submit generations
- Configurable interval between every jobs
- Enable and disable extension whenever
- Detect current model and fetch corresponding jobs on the fly
- Show generation images in the Stable Diffusion WebUI
- Save generation images with png info text to local
Install
-
Run the following command in the root directory of your Stable Diffusion WebUI installation:
git clone https://github.com/sdwebui-w-horde/sd-webui-stable-horde-worker.git extensions/stable-horde-worker -
Launch the Stable Diffusion WebUI, You would see the
Stable Horde Workertab page.
-
Register an account on Stable Horde and get your
API keyif you don't have one.Note: the default anonymous key
00000000is not working for a worker, you need to register an account and get your own key. -
Setup your
API keyhere. -
Setup
Worker namehere with a proper name. -
Make sure
Enableis checked. -
Click the
Apply settingsbuttons.
Stable Horde
Stable Horde Client
https://github.com/natanjunges/stable-diffusion-webui-stable-horde
Generate pictures using other user's PC. You should be able to receive images from the stable horde with anonymous 0000000000 api key, however it is recommended to get your own - https://stablehorde.net/register
Note: Retrieving Images may take 2 minutes or more, especially if you have no kudos.
Multiple hypernetworks
https://github.com/antis0007/sd-webui-multiple-hypernetworks
Extension that allows the use of multiple hypernetworks at once

Hypernetwork-Monkeypatch-Extension
https://github.com/aria1th/Hypernetwork-MonkeyPatch-Extension
Extension that provides additional training features for hypernetwork training, and supports multiple hypernetworks.

Ultimate SD Upscaler
https://github.com/Coyote-A/ultimate-upscale-for-automatic1111

More advanced options for SD Upscale, less artifacts than original using higher denoise ratio (0.3-0.5).
Model Converter
https://github.com/Akegarasu/sd-webui-model-converter
Model convert extension, supports convert fp16/bf16 no-ema/ema-only safetensors.
Kohya-ss Additional Networks
https://github.com/kohya-ss/sd-webui-additional-networks
Allows the Web UI to use networks (LoRA) trained by their scripts to generate images. Edit safetensors prompt and additional metadata, and use 2.X LoRAs.

Add image number to grid
https://github.com/AlUlkesh/sd_grid_add_image_number
Add the image's number to its picture in the grid.
quick-css
https://github.com/Gerschel/sd-web-ui-quickcss
Extension for quickly selecting and applying custom.css files, for customizing look and placement of elements in ui.


Prompt Generator
https://github.com/imrayya/stable-diffusion-webui-Prompt_Generator
Adds a tab to the webui that allows the user to generate a prompt from a small base prompt. Based on FredZhang7/distilgpt2-stable-diffusion-v2.

model-keyword
https://github.com/mix1009/model-keyword
Inserts matching keyword(s) to the prompt automatically. Update extension to get the latest model+keyword mappings.

sd-model-preview
https://github.com/Vetchems/sd-model-preview
Allows you to create a txt file and jpg/png's with the same name as your model and have this info easily displayed for later reference in webui.

Enhanced-img2img
https://github.com/OedoSoldier/enhanced-img2img
An extension with support for batched and better inpainting. See readme for more details.

openOutpaint extension
https://github.com/zero01101/openOutpaint-webUI-extension
A tab with the full openOutpaint UI. Run with the --api flag.

Save Intermediate Images
https://github.com/AlUlkesh/sd_save_intermediate_images
Implements saving intermediate images, with more advanced features.



Riffusion
https://github.com/enlyth/sd-webui-riffusion
Use Riffusion model to produce music in gradio. To replicate original interpolation technique, input the prompt travel extension output frames into the riffusion tab.


DH Patch
https://github.com/d8ahazard/sd_auto_fix
Random patches by D8ahazard. Auto-load config YAML files for v2, 2.1 models; patch latent-diffusion to fix attention on 2.1 models (black boxes without no-half), whatever else I come up with.
Preset Utilities
https://github.com/Gerschel/sd_web_ui_preset_utils
Preset tool for UI. Supports presets for some custom scripts.

Config-Presets
https://github.com/Zyin055/Config-Presets
Adds a configurable dropdown to allow you to change UI preset settings in the txt2img and img2img tabs.

Diffusion Defender
https://github.com/WildBanjos/DiffusionDefender
Prompt blacklist, find and replace, for semi-private and public instances.
NSFW checker
https://github.com/AUTOMATIC1111/stable-diffusion-webui-nsfw-censor
Replaces NSFW images with black.
Infinity Grid Generator
https://github.com/mcmonkeyprojects/sd-infinity-grid-generator-script
Build a yaml file with your chosen parameters, and generate infinite-dimensional grids. Built-in ability to add description text to fields. See readme for usage details.

embedding-inspector
https://github.com/tkalayci71/embedding-inspector
Inspect any token(a word) or Textual-Inversion embeddings and find out which embeddings are similar. You can mix, modify, or create the embeddings in seconds. Much more intriguing options have since been released, see here.

Prompt Gallery
https://github.com/dr413677671/PromptGallery-stable-diffusion-webui
Build a yaml file filled with prompts of your character, hit generate, and quickly preview them by their word attributes and modifiers.

DAAM
https://github.com/toriato/stable-diffusion-webui-daam
DAAM stands for Diffusion Attentive Attribution Maps. Enter the attention text (must be a string contained in the prompt) and run. An overlapping image with a heatmap for each attention will be generated along with the original image.

Visualize Cross-Attention
https://github.com/benkyoujouzu/stable-diffusion-webui-visualize-cross-attention-extension
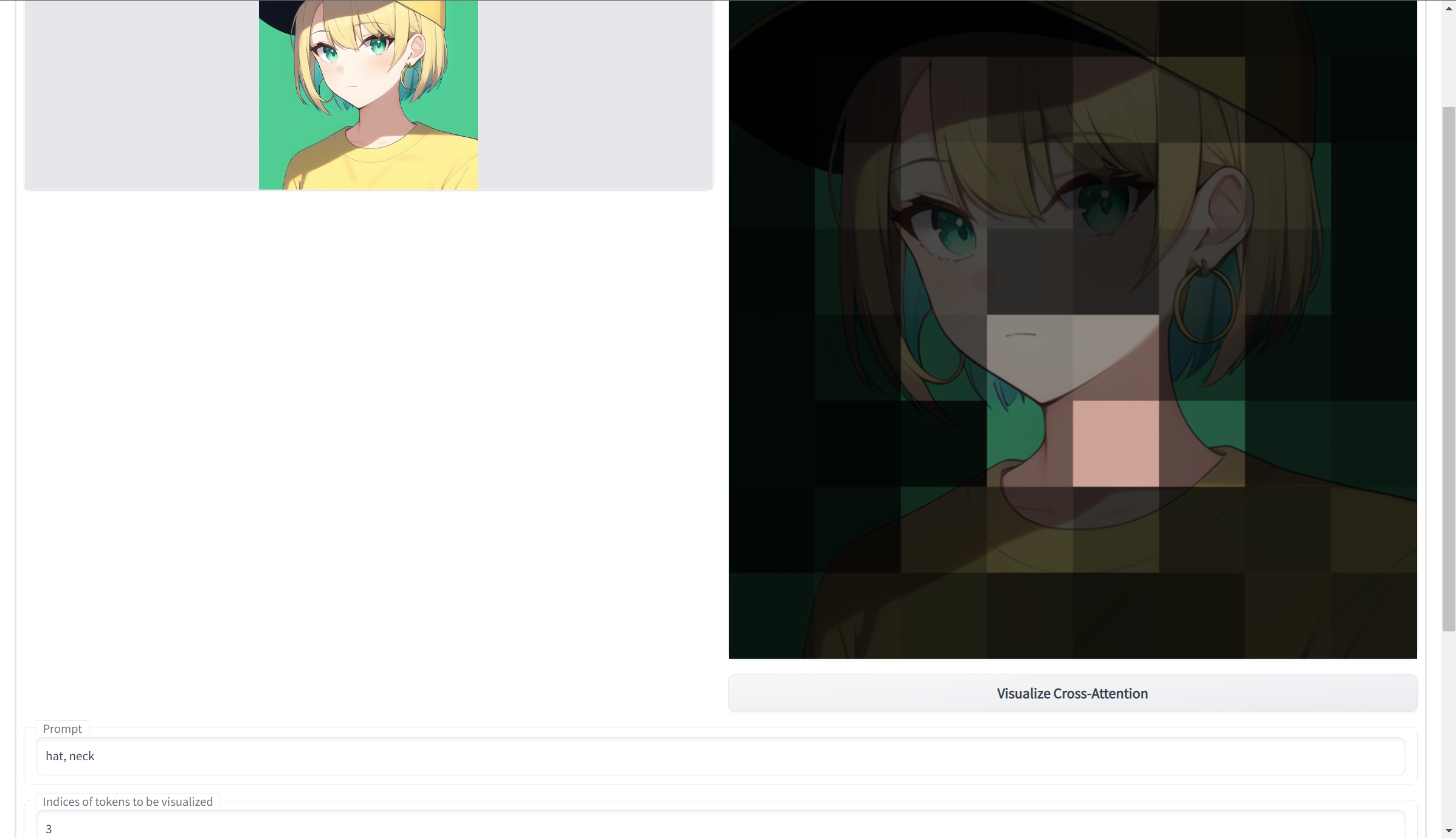
Generates highlighted sectors of a submitted input image, based on input prompts. Use with tokenizer extension. See the readme for more info.
ABG_extension
https://github.com/KutsuyaYuki/ABG_extension
Automatically remove backgrounds. Uses an onnx model fine-tuned for anime images. Runs on GPU.
 |
 |
 |
 |
|---|---|---|---|
 |
 |
 |
 |
depthmap2mask
https://github.com/Extraltodeus/depthmap2mask
Create masks for img2img based on a depth estimation made by MiDaS.



multi-subject-render
https://github.com/Extraltodeus/multi-subject-render
It is a depth aware extension that can help to create multiple complex subjects on a single image. It generates a background, then multiple foreground subjects, cuts their backgrounds after a depth analysis, paste them onto the background and finally does an img2img for a clean finish.

Depth Maps
https://github.com/thygate/stable-diffusion-webui-depthmap-script
Creates depthmaps from the generated images. The result can be viewed on 3D or holographic devices like VR headsets or lookingglass display, used in Render or Game- Engines on a plane with a displacement modifier, and maybe even 3D printed.

Merge Board
https://github.com/bbc-mc/sdweb-merge-board
Multiple lane merge support(up to 10). Save and Load your merging combination as Recipes, which is simple text.

also see:
https://github.com/Maurdekye/model-kitchen
gelbooru-prompt
https://github.com/antis0007/sd-webui-gelbooru-prompt
Fetch tags using your image's hash.
booru2prompt
https://github.com/Malisius/booru2prompt
This SD extension allows you to turn posts from various image boorus into stable diffusion prompts. It does so by pulling a list of tags down from their API. You can copy-paste in a link to the post you want yourself, or use the built-in search feature to do it all without leaving SD.

also see:
https://github.com/stysmmaker/stable-diffusion-webui-booru-prompt
WD 1.4 Tagger
https://github.com/toriato/stable-diffusion-webui-wd14-tagger
Uses a trained model file, produces WD 1.4 Tags. Model link - https://mega.nz/file/ptA2jSSB#G4INKHQG2x2pGAVQBn-yd_U5dMgevGF8YYM9CR_R1SY

DreamArtist
https://github.com/7eu7d7/DreamArtist-sd-webui-extension
Towards Controllable One-Shot Text-to-Image Generation via Contrastive Prompt-Tuning.

Auto TLS-HTTPS
https://github.com/papuSpartan/stable-diffusion-webui-auto-tls-https
Allows you to easily, or even completely automatically start using HTTPS.
Randomize
https://github.com/stysmmaker/stable-diffusion-webui-randomize
fork: https://github.com/innightwolfsleep/stable-diffusion-webui-randomize
Allows for random parameters during txt2img generation. This script is processed for all generations, regardless of the script selected, meaning this script will function with others as well, such as AUTOMATIC1111/stable-diffusion-webui-wildcards.
conditioning-highres-fix
https://github.com/klimaleksus/stable-diffusion-webui-conditioning-highres-fix
This is Extension for rewriting Inpainting conditioning mask strength value relative to Denoising strength at runtime. This is useful for Inpainting models such as sd-v1-5-inpainting.ckpt

Detection Detailer
https://github.com/dustysys/ddetailer
An object detection and auto-mask extension for Stable Diffusion web UI.

Sonar
https://github.com/Kahsolt/stable-diffusion-webui-sonar
Improve the generated image quality, searches for similar (yet even better!) images in the neighborhood of some known image, focuses on single prompt optimization rather than traveling between multiple prompts.


prompt travel
https://github.com/Kahsolt/stable-diffusion-webui-prompt-travel
Extension script for AUTOMATIC1111/stable-diffusion-webui to travel between prompts in latent space.
Example: (Click to expand:)

shift-attention
https://github.com/yownas/shift-attention
Generate a sequence of images shifting attention in the prompt. This script enables you to give a range to the weight of tokens in a prompt and then generate a sequence of images stepping from the first one to the second.
seed travel
https://github.com/yownas/seed_travel
Small script for AUTOMATIC1111/stable-diffusion-webui to create images that exists between seeds.
Example: (Click to expand:)

Embeddings editor
https://github.com/CodeExplode/stable-diffusion-webui-embedding-editor
Allows you to manually edit textual inversion embeddings using sliders.

Latent Mirroring
https://github.com/dfaker/SD-latent-mirroring
Applies mirroring and flips to the latent images to produce anything from subtle balanced compositions to perfect reflections

StylePile
https://github.com/some9000/StylePile
An easy way to mix and match elements to prompts that affect the style of the result.

Push to 🤗 Hugging Face
https://github.com/camenduru/stable-diffusion-webui-huggingface

To install it, clone the repo into the extensions directory and restart the web ui:
git clone https://github.com/camenduru/stable-diffusion-webui-huggingface
pip install huggingface-hub
Tokenizer
https://github.com/AUTOMATIC1111/stable-diffusion-webui-tokenizer
Adds a tab that lets you preview how CLIP model would tokenize your text.

novelai-2-local-prompt
https://github.com/animerl/novelai-2-local-prompt
Add a button to convert the prompts used in NovelAI for use in the WebUI. In addition, add a button that allows you to recall a previously used prompt.

Booru tag autocompletion
https://github.com/DominikDoom/a1111-sd-webui-tagcomplete
Displays autocompletion hints for tags from "image booru" boards such as Danbooru. Uses local tag CSV files and includes a config for customization.

Unprompted
https://github.com/ThereforeGames/unprompted
Supercharge your prompt workflow with this powerful scripting language!

Unprompted is a highly modular extension for AUTOMATIC1111's Stable Diffusion Web UI that allows you to include various shortcodes in your prompts. You can pull text from files, set up your own variables, process text through conditional functions, and so much more - it's like wildcards on steroids.
While the intended usecase is Stable Diffusion, this engine is also flexible enough to serve as an all-purpose text generator.
training-picker
https://github.com/Maurdekye/training-picker
Adds a tab to the webui that allows the user to automatically extract keyframes from video, and manually extract 512x512 crops of those frames for use in model training.

Installation
- Install AUTOMATIC1111's Stable Diffusion Webui
- Install ffmpeg for your operating system
- Clone this repository into the extensions folder inside the webui
- Drop videos you want to extract cropped frames from into the training-picker/videos folder
auto-sd-paint-ext
https://github.com/Interpause/auto-sd-paint-ext
Extension for AUTOMATIC1111's webUI with Krita Plugin (other drawing studios soon?)

- Optimized workflow (txt2img, img2img, inpaint, upscale) & UI design.
- Only drawing studio plugin that exposes the Script API.
See https://github.com/Interpause/auto-sd-paint-ext/issues/41 for planned developments. See CHANGELOG.md for the full changelog.
Dataset Tag Editor
https://github.com/toshiaki1729/stable-diffusion-webui-dataset-tag-editor
This is an extension to edit captions in training dataset for Stable Diffusion web UI by AUTOMATIC1111.
It works well with text captions in comma-separated style (such as the tags generated by DeepBooru interrogator).
Caption in the filenames of images can be loaded, but edited captions can only be saved in the form of text files.

Aesthetic Image Scorer
https://github.com/tsngo/stable-diffusion-webui-aesthetic-image-scorer
Extension for https://github.com/AUTOMATIC1111/stable-diffusion-webui
Calculates aesthetic score for generated images using CLIP+MLP Aesthetic Score Predictor based on Chad Scorer
See Discussions
Saves score to windows tags with other options planned

Artists to study
https://github.com/camenduru/stable-diffusion-webui-artists-to-study
https://artiststostudy.pages.dev/ adapted to an extension for web ui.
To install it, clone the repo into the extensions directory and restart the web ui:
git clone https://github.com/camenduru/stable-diffusion-webui-artists-to-study
You can add the artist name to the clipboard by clicking on it. (thanks for the idea @gmaciocci)

Deforum
https://github.com/deforum-art/deforum-for-automatic1111-webui
The official port of Deforum, an extensive script for 2D and 3D animations, supporting keyframable sequences, dynamic math parameters (even inside the prompts), dynamic masking, depth estimation and warping.

Inspiration
https://github.com/yfszzx/stable-diffusion-webui-inspiration
Randomly display the pictures of the artist's or artistic genres typical style, more pictures of this artist or genre is displayed after selecting. So you don't have to worry about how hard it is to choose the right style of art when you create.

Image Browser
https://github.com/AlUlkesh/stable-diffusion-webui-images-browser
Provides an interface to browse created images in the web browser, allows for sorting and filtering by EXIF data.

Smart Process
https://github.com/d8ahazard/sd_smartprocess
Intelligent cropping, captioning, and image enhancement.

Dreambooth
https://github.com/d8ahazard/sd_dreambooth_extension
Dreambooth in the UI. Refer to the project readme for tuning and configuration requirements. Includes LoRA (Low Rank Adaptation)
Based on ShivamShiaro's repo.
Dynamic Prompts
https://github.com/adieyal/sd-dynamic-prompts
A custom extension for AUTOMATIC1111/stable-diffusion-webui that implements an expressive template language for random or combinatorial prompt generation along with features to support deep wildcard directory structures.
More features and additions are shown in the readme.

Using this extension, the prompt:
A {house|apartment|lodge|cottage} in {summer|winter|autumn|spring} by {2$$artist1|artist2|artist3}
Will any of the following prompts:
- A house in summer by artist1, artist2
- A lodge in autumn by artist3, artist1
- A cottage in winter by artist2, artist3
- ...
This is especially useful if you are searching for interesting combinations of artists and styles.
You can also pick a random string from a file. Assuming you have the file seasons.txt in WILDCARD_DIR (see below), then:
__seasons__ is coming
Might generate the following:
- Winter is coming
- Spring is coming
- ...
You can also use the same wildcard twice
I love __seasons__ better than __seasons__
- I love Winter better than Summer
- I love Spring better than Spring
Wildcards
https://github.com/AUTOMATIC1111/stable-diffusion-webui-wildcards
Allows you to use __name__ syntax in your prompt to get a random line from a file named name.txt in the wildcards directory.
Aesthetic Gradients
https://github.com/AUTOMATIC1111/stable-diffusion-webui-aesthetic-gradients
Create an embedding from one or few pictures and use it to apply their style to generated images.

3D Model&Pose Loader
https://github.com/jtydhr88/sd-3dmodel-loader
A custom extension that allows you to load your local 3D model/animation inside webui, or edit pose as well, then send screenshot to txt2img or img2img as your ControlNet's reference image.

Canvas Editor
https://github.com/jtydhr88/sd-canvas-editor
A custom extension for sd-webui that integrated a full capability canvas editor which you can use layer, text, image, elements, etc.

One Button Prompt
https://github.com/AIrjen/OneButtonPrompt
One Button Prompt is a tool/script for automatic1111 for beginners who have problems writing a good prompt, or advanced users who want to get inspired.
It generates an entire prompt from scratch. It is random, but controlled. You simply load up the script and press generate, and let it surprise you.

Model Downloader
https://github.com/Iyashinouta/sd-model-downloader
SD-Webui extension to Download Model from CivitAI and HuggingFace, Recomended for Cloud Users (a.k.a Google Colab, etc.)

SD Telegram
https://github.com/amputator84/sd_telegram
Telegram bot on aiogram to generate images in automatic1111 locally (127.0.0.1:7860 nowebui)
if you want to manage it via telegram bot, install it via extensions. Further instructions are on github. The bot uses sdwebuiapi and works with a local address.
Able to generate previews, full-size pictures, also send documents and groups.
Able to "compose" prompts, take them from lexica, there is a stream generation script for all models.
QR Code Generator
https://github.com/missionfloyd/webui-qrcode-generator
Instantly generate QR Codes for ControlNet.
